🤖 Copilot
Copilot is an EXPERIMENTAL TEXT2SQL interface that uses Generative AI to convert human input into SQL code that you can execute inline with the conversation.
If you use ChatGPT or similar chat-based interfaces, you already know how to use it. Actually, if you ever used any Messenger or WhatsAPP you do. Just imagine you have a great guy on the other side, that is not only a Postgres and SQL pro, but also knows what your database is about and what's inside it.
Well, it PARTIALLY KNOWS WHAT'S INSIDE.
Right now, Copilot know about your database structure: schemas, tables, fields, constraints and indexes.
Data Privacy First
👉 It DOESN'T KNOW ABOUT YOUR DATA!!!
And this is both a pro and a cons:
On one side, your privacy is guaranteed (check the source code! It's all open for you to read) and you can safely run Copilot on a production database knowing that your data - or your customers' data - is not sent to the LLM.
On the other side, not knowing the data is a limitation to Copilot's ability in crafting performant queries. After all, knowing the data is the core foundation of database optimization!
🔥 I have in mind to let Copilot take samples of the data in the future, but that will be a strictly opt-in feature that you will have to enable via environmental variable.
No data will EVER be sent around without your explicit request/consent.
Current Engine
PGMate's Copilot runs on OpenAI APIs.
This means that you can quickly switch to any provider that is compatible with it, like DeepSeek or Qwen.
docker run ... \
-e PGMATE_OPENAPI_KEY=xxx \
-e PGMATE_OPENAPI_URL=https://other-api.ai
🚧 Copilot still uses gpt-4o and gpt-4o-mini as models names, but we will soon expose and ENV configuration to map the model to a strong and fast abstration in the name.
Current Capabilities
I've run pair programming sessions in which I managed to build, seed, and query a failrily complex schema aimed to support a School of Rock scenario.
For less than $0.03.
😎
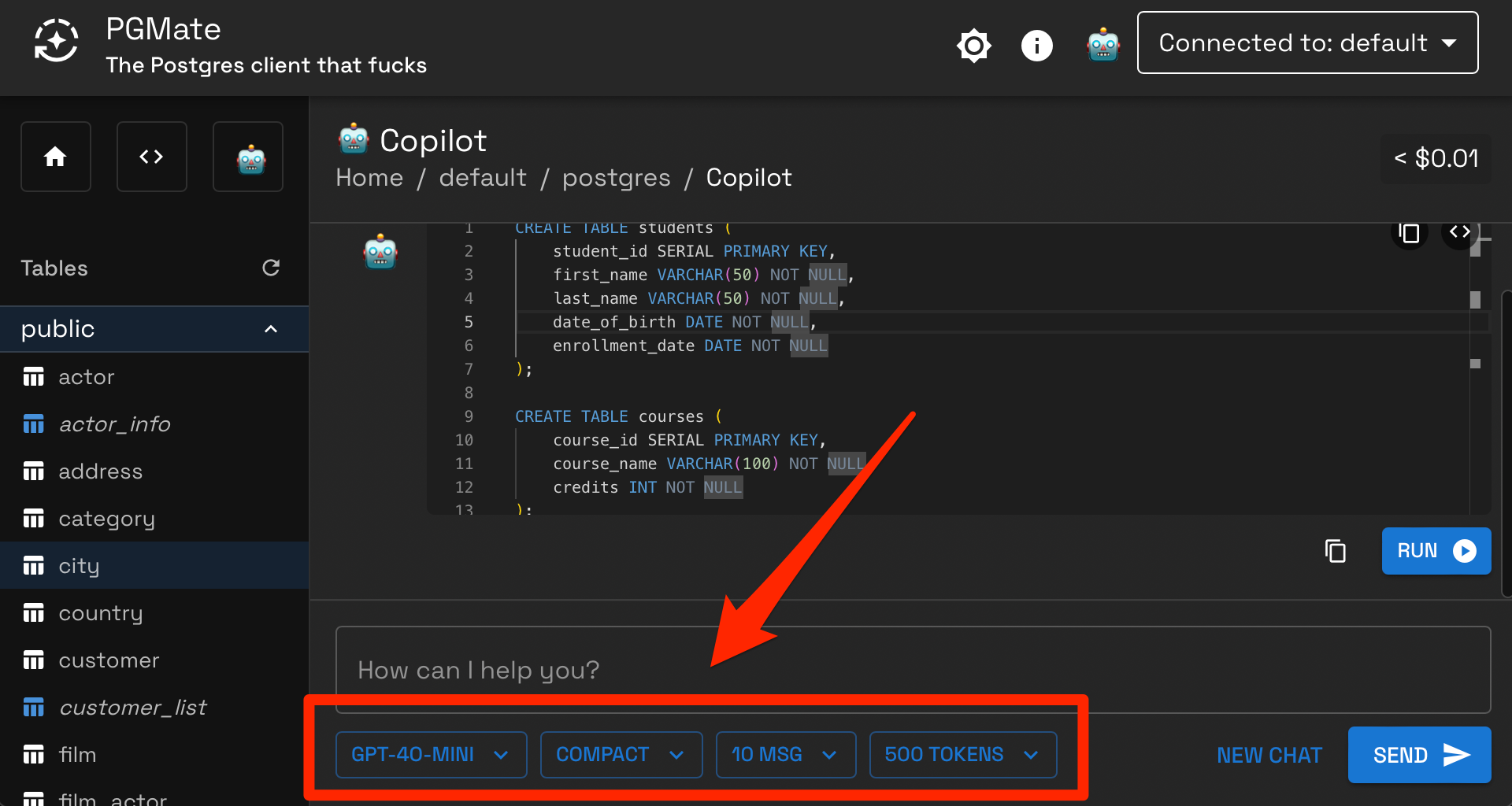
Copilot defaults to a fast model (gpt-4o-mini) and a compact context (table and fields names) for cost optimization. You can switch to a stronger model (gpt-4o) and a full context (adds field types, constraints, indexes) for complex requests using the UI's toggles:
Development Plans
LLM Abstraction
I don't believe in abstractions such as ORMs and alikes. It is my opinion and experience that mastering your tool of choiche yields the best results. That's why I use Postgres by the way...
Even in the world of LLM this stands true.
The way a prompt needs to be phrased is influenced by the model that will consume it. For different models focuses on different aspects.
Nevertheless, we are still in the early days of GenAI and being flexible is important.
PGMate will be model-agnostic AND model-specific with this approach:
- You will be able to use any provider that is compatible with OpenAI APIs structure through ENV VARS.
(looks like the world of LLMs have accepted it as a de-facto standard)
- You will be able to associate any model to a map of names (Eg.
strongandfast) - You will be able to customize the prompts by writing particular prompt-files and mapping a volume
This approach should yield the best combination of flexibility and customization.
I hope the communitiy will join on and help building a library of prompts so that PGMate will be able to switch to the most appropriate prompt based on the model selected by the user.
I envision this to be the best possible outcome, so the user only have to provide an API KEY to any of the supported providers.
Improve Context Structure
Right now the context that PGMate provides is list-based (list of {schema}.{table} with a list of fields inside). But I've recently found out that hierarchical structures are better for LLMs.
This seems to be a low-hanging fruit in improving Copilot's performances, so I will definitely work on it soon. You can also join in and edit the mapping functions ❤️.
Layered Approach
Another approach to improve the LLMs performance is to introduce a two-step approach:
- Ask the model to reduce a broad but shallow context into a list of objects needed to solve the problem
- Ask the model to solve the problem using a narrow but deep context crafted out of the first step's selection
This should balance token consumption and completeness of the information that are passed to the model.
I'm also studying hard on tokens prioritization and I have in mind to craft a ranking algorithm that is partially euristic-based and LLM-based, so that the context is sorted by ranking in the scope of the problem that the user is presenting.
Context Vectorization
The idea is to craft a deep context out of any object, hash it and vectorize it in the default database for any given connection. Such vector db would be kept in sync by a background process that watches schema-changes on an active connection, and updates the vectors of the portions of the schema that have changed.
The layered approach that we describle could either replace the first step with a local vector based search (basically we would go RAG), or introduce a first step in which the broad by shallow context is pre-filtered by RAG.
Although I'm positive this will help with cost management (embeddings are much cheaper than tokens), I'm not sure this will work well. We will have to try.
Manual Context Settings
The idea is to add a settings panel with a schema tree (schema / table / [fields | constraints | indexes]) and let the user check/uncheck the objects that need to be passed down to the LLM.
👉 A simple toggle could help switching from manual to automated mode pretty much like your car does.
This approach requires enough human-knowledge to know which parts of the schema are relevant for the next request, offsetting the task of writing the code to the LLM.
I believe this is a high performing approach.
🤷♂️ I also love the "human in the loop" concept, for I wish with all my heart NOT TO BE REPLACED by the AI.
Data Spaces
This is not my idea. It's Uber's.
In the linked paper they simply introduce a "step zero" in the layered approach and manually craft multiple manual contexts that are stored in a vectorized table.
Each space (well, it's just a selection of schema / table / [fields | constraints | indexes]) would have a name and a description. The description is vectorized so that the first step in the "layered approach" described above would be to use a fast LLM to match the most appropriate space by intention.
How well this matching would work depends on how well the space's description is matched by the user's request at chat-time.
Also in this case, I love the idea of introducing the spaces AND letting the user manually choose which space to use during a chat interaction.
Again, I really wish I will still be relevant 5 years down the line 🤣.
Chat History Summarization
I'm a rather poor guy. I've born in a humble hard-working family, and money have always been a scarce resource. So most of my work and my efforts go in the direction of cost optimization 😇.
I have 3 ideas how to keep tokens consumption down to a capped linear growth:
The dumb idea is to truncate the chat history. That's what Copilot does today, and what many simple tools out there do as well. Today the default truncation is at 10 messages, and I've found it works great because the model is constanly fed with fresh info about the schema, so it doesn't need to remember a table that was created 15 messages ago. It knows it anyway.
But this is still a bit dumb as an approach. We may end up finding out that DUMB IS BEST, but I would like to give it a go with two less dumb approaches.
The classic summary message. This consist in asking an independent model to keep summarizing old messages, feeding the LLM with:
- old summarized History
- X fresh messages (5->10)
- the new user request
- the schema context
This approach consumes tokens to keep refining the summary, and it introduces some challenges in keeping a relevant-first list into the summary so to kick out less-relevant information once the summary reaches a max-size.
As far as I understand, this is what tools like ChatGPT do under the hood.
Another approach that I'd like to try is simply to ask a sidekick LLM to minify the last user request by removing all the human level language that don't provide meaning to the llm.
A request like PLEASE GIVE ME THE NEW USERS would at the very least remove the word PLEASE from the chat history.
This way, PGMate would maintain a parallel chat with the "compressed messages". And this invisible history could be capped (the dump approach) or summarized (as describle before) as well.
All of this will require time to implement and KPIs to assess how good the approach is!
Data Sampling
This is an extremely delicate subject because sending your own data into the unknown is scary, and it could be illegal as well 👮.
On the other hands, it is well known that the only real approach to data optimization is:
👉 KNOW YOUR DATA 👈.
Allowing PGMate to grap SOME data from the refined context, and sending those data into the LLM could improve the results. Especially when combined with indexes information.
I made some empirical tests using plain ChatGPT and manually crafted contexts, and the model yields different queries with different plans. So I believe this could be relevant for improving the quality of the resulting code.
This feature must be implemented as STRICTLY OPT-IN so there could be no scenario in which a PGMate user says "I didn't know my data was exposed". That would not be acceptable.
As last consideration, I don't think it would be an issue to share with the model development datasets or anonymized production ones.
I envision an anonymized data sampler that can apply fixed rules for scrambling the data that are sent into the LLM.
Extended Statistics
The current version of Copilot already taps into Postgres default statistics to send in the estimated rows into the LLM.
This should be extended with unique values, the instogram etc... As well as info from pg_stats when enabled.
Gathering the information is rather easy, figuring out how much of this information needs to be provided - hence balancing the cost-to-performance - is another thing.
I don't have ideas about it.
Yet.